Understanding cosine similarity
Cosine Similarity is an algorithm to measure similarity between two vectors, whether they be document vectors, image vectors, pose keypoints as vectors, or any two lists of numbers.
Preamble
I first got interested in cosine similarity when the article on MoveMirror mentioned that they used it to match poses. That article led me to this very clear explanation.
Having previously seen the effectiveness of cosine similarity in Word2Vec model interpretations, where you have a word / sentence / document embedded in a vector space (generally a vector of a length of around 300), and you use them to find similar words / sentences / documents through cosine similarity, I decided to dig deeper to understand why it works the way it does.
The following is thus the slightly more visual explanation of the answer by mjv from stack overflow.
a use case
If you're interested in a visual 'explanation' (not really) or mainly just the algorithm running on two pose datasets, please visit this link
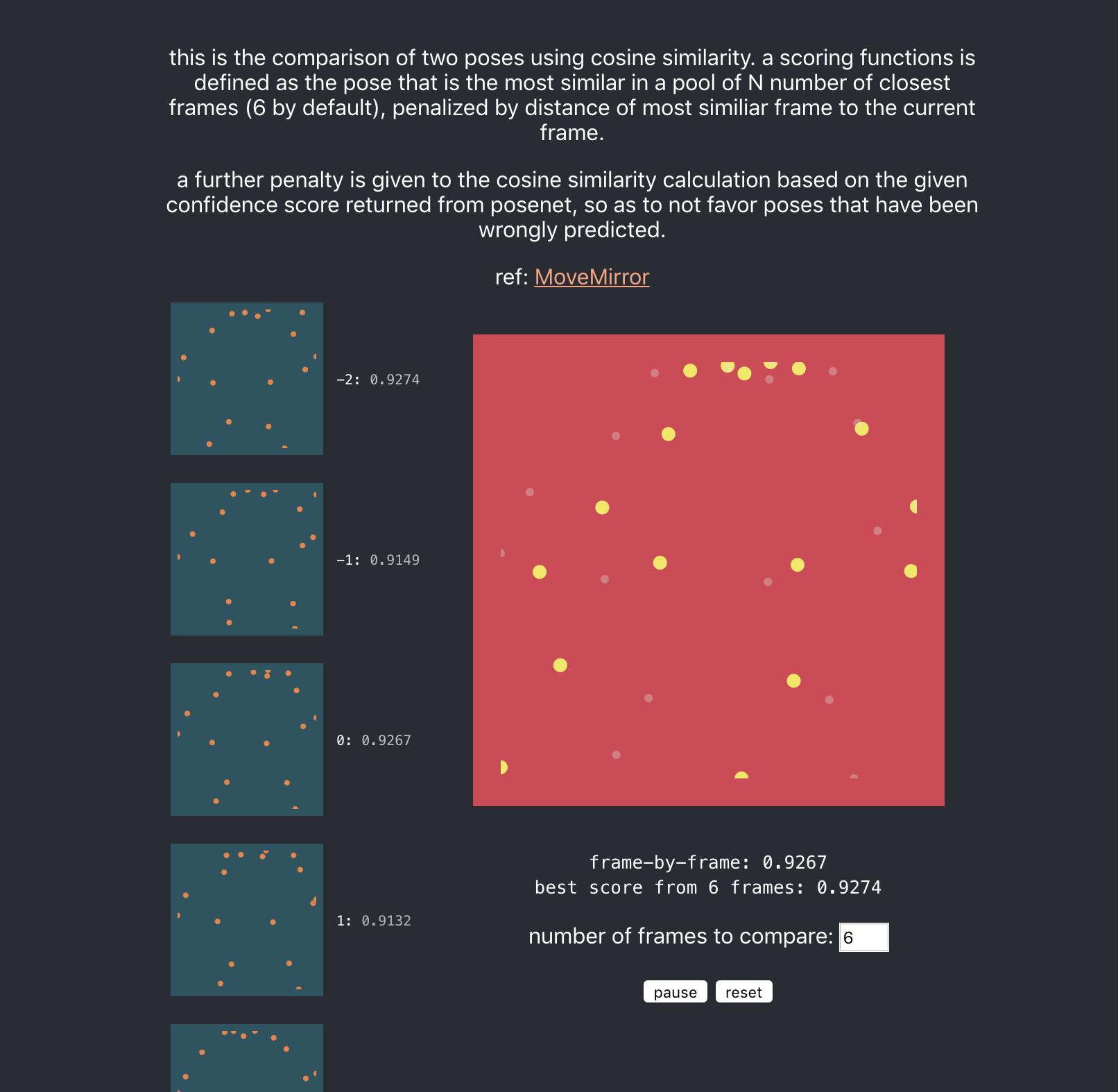
How cosine similarity works
####this example starts with 2 dimensions (comparing vectors in just two dimensions)
Say you are comparing two documents.
document 1
The rain in london falls mainly in paris, france. Paris is a nice place. Paris is affectionately called "Paris" by its inhabitants, while it is called Paris by other people around the world (...250 words)
document 2
London is a cloudy place to be, and while it is not as wet as London, it doesn't hold a candle to Paris, where 350 days of the year is covered by paris clouds reminiscent of paris movies in the famous paris days. I need to add 4 more instances of the word "Paris" here and am finding it very hard even with allowance for making nonsensical but grammatically correct sentences. Paris is a hard thing to make a paris-like sentence from. Or so the people from Paris like to boast. (...1000 words)
doesn't make sense, but bear with me.
todo: generate victory charts from markdown
####document 1 has 1 count of 'London' and 4 counts of 'Paris'.
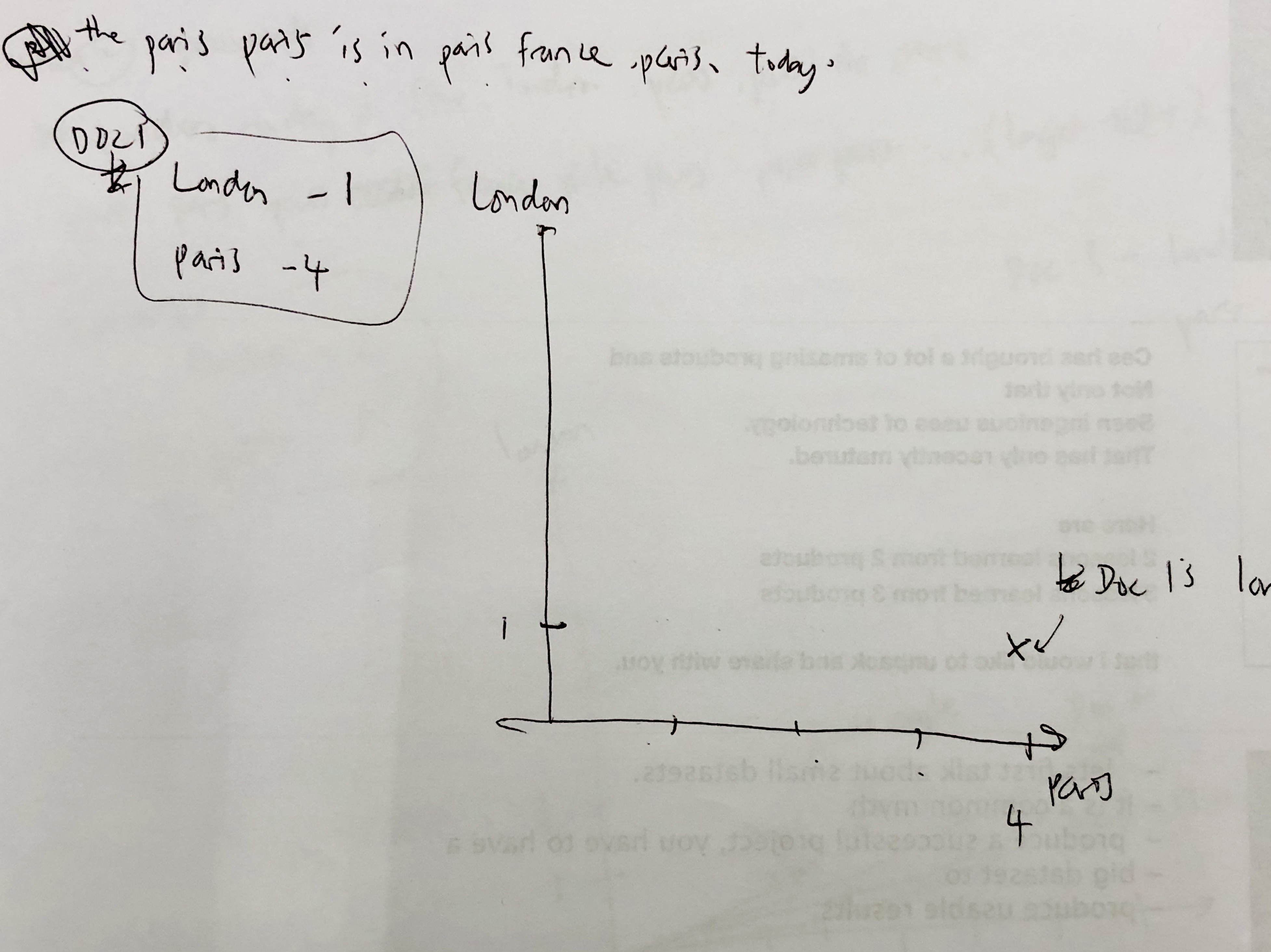
this is what it looks like on a London-Paris scale.
####document 2 has 2 counts of 'London' and 8 counts of 'Paris'.
the question is: is document 1 similar to document 2 in terms of each document's emphasis on london and paris?
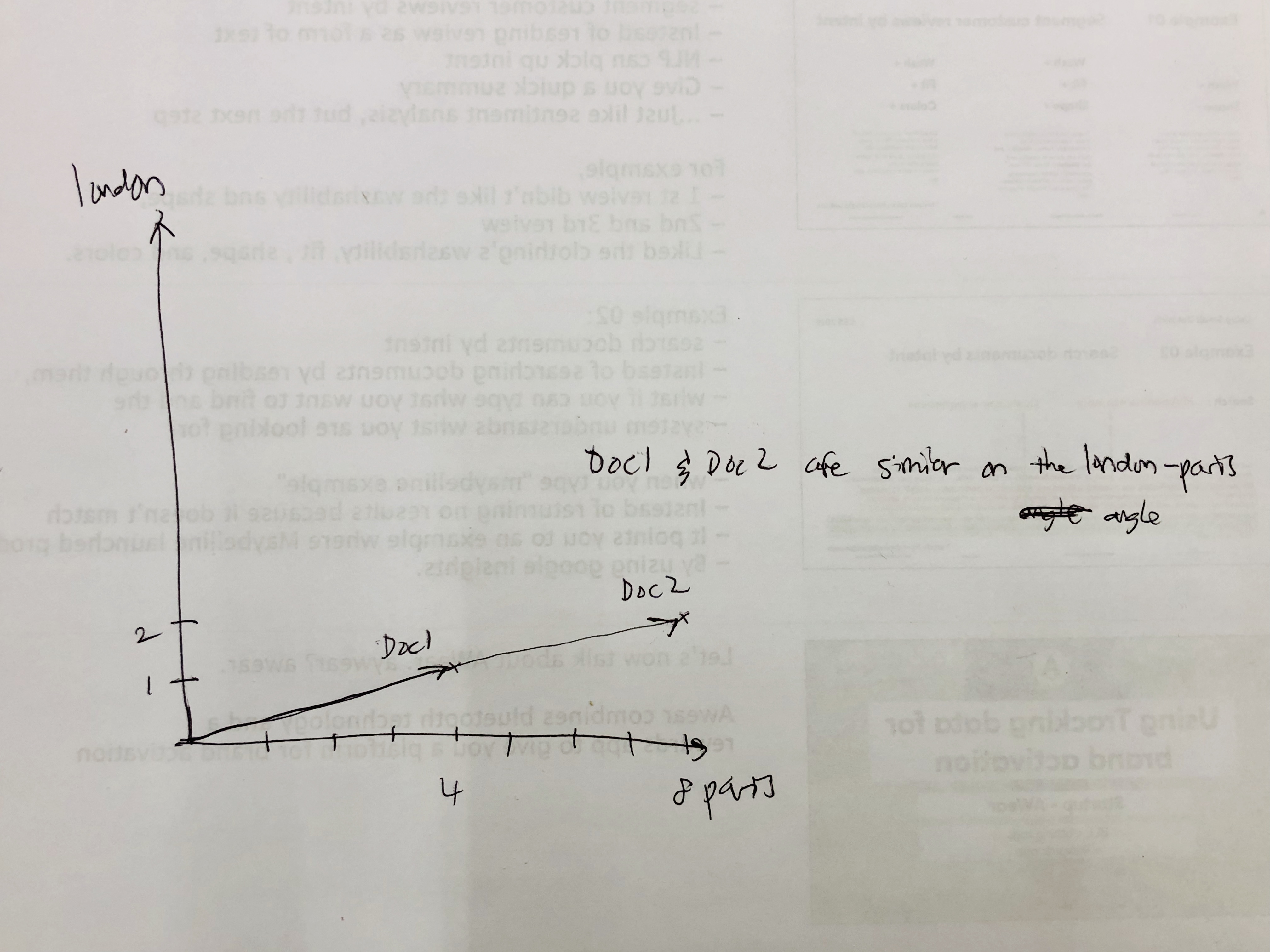
yes. because they are both proportionate to each other. their emphasis is the same.
What about another document with different counts for each? say..
####document 3 has 1 count of 'London' and 5 counts of 'Paris'.
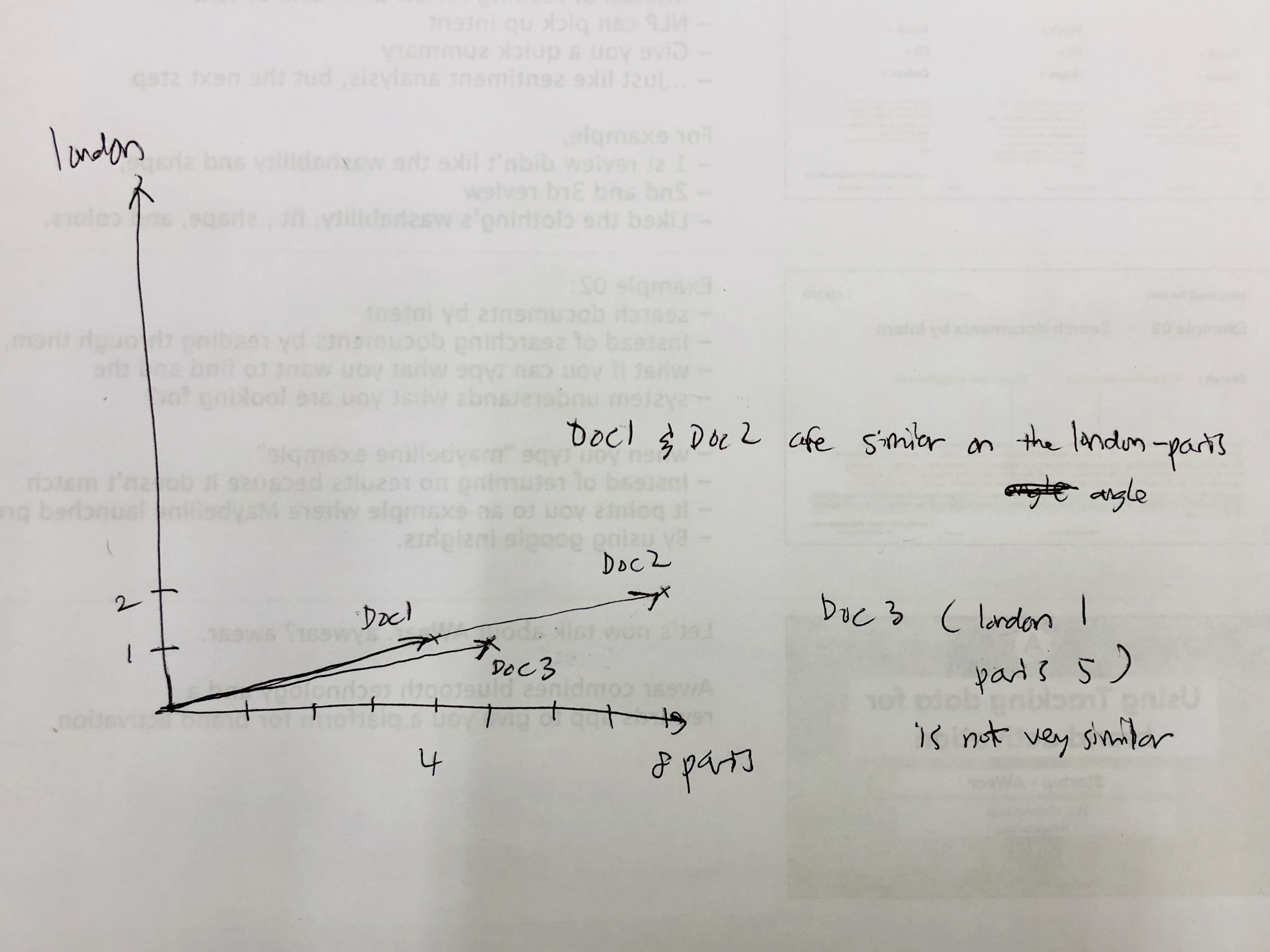
indeed, because document 3 places a different emphasis on these two words, it is less similar to document 1, when compared to document 2.
If we did a search for documents that are similar to document 1, if the search only takes into account the two terms 'London' and 'Paris', the results will be:
- document 2
- document 3
###3 dimensions
Say we also want to see a similarity between 3 terms, 'London', 'Paris', and 'Amsterdam'. And, say:
- Document 1 has the term count of:
- London: 1
- Paris: 4
- Amsterdam: 3
- Document 2 has the term count of:
- London: 2
- Paris: 8
- Amsterdam: 1
- Document 3 has the term count of:
- London: 1
- Paris: 5
- Amsterdam: 8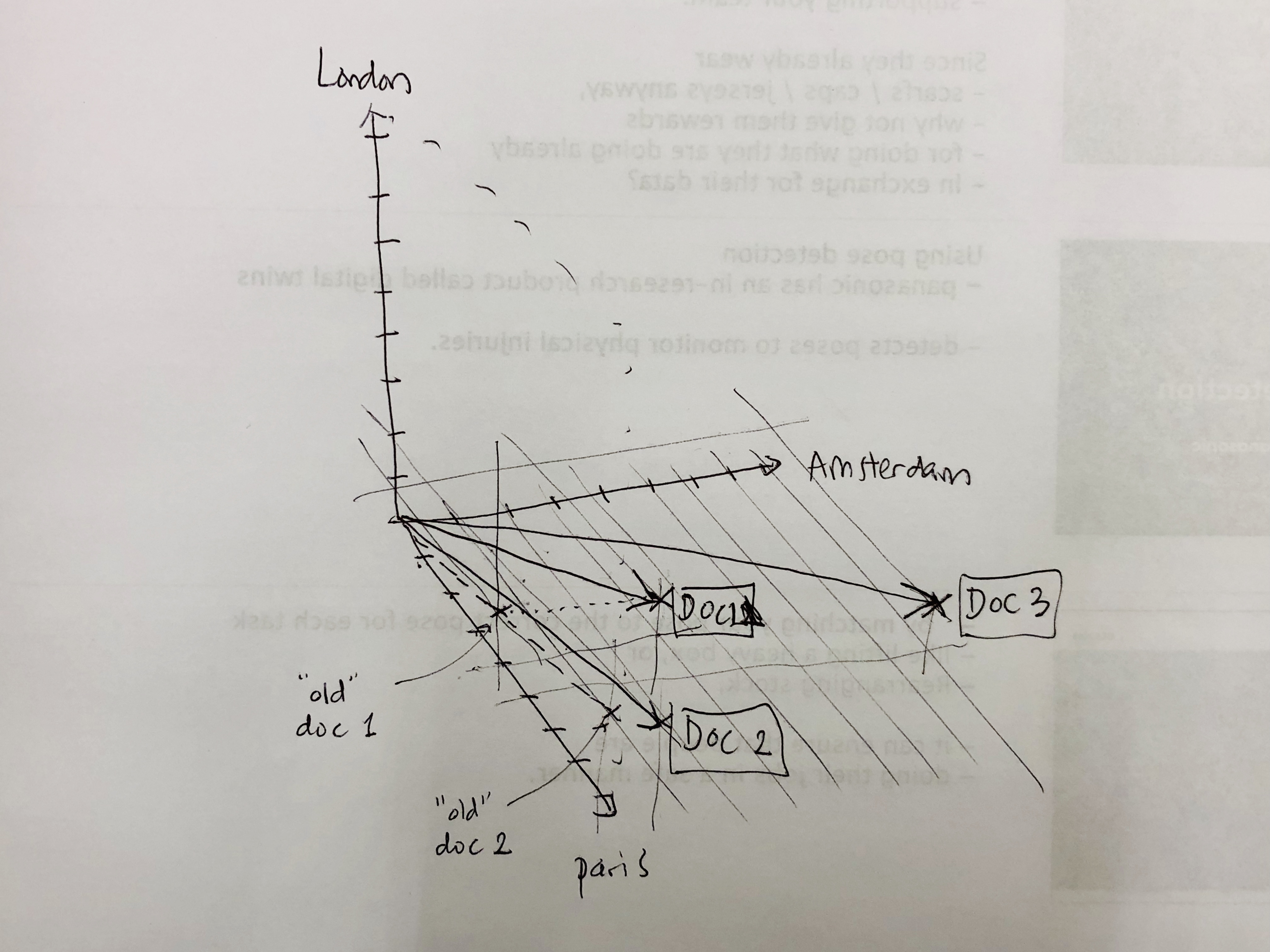
you will notice that similarity (in angles) starts to diverge. document 1 and document 2 are no longer 100% matches, but they are still very similar.
###300 dimensions
now imagine the same thing in a 300 dimensional space. All cosine similarity is doing is comparing (normalized) angles in this high dimensional space.
cosine similarity = vector angle similarity, normalized.

or, in the words of the person who explained this in stack overflow, mjv,
Bam! by measuring the angle between the vectors, we can get a good idea of their similarity , and, to make things even easier, by taking the Cosine of this angle, we have a nice 0 to 1 (or -1 to 1, depending what and how we account for) value that is indicative of this similarity. The smaller the angle, the bigger (closer to 1) the cosine value, and also the bigger the similarity.
Why it works
Code
Nish Tahir has code in Typescript that works for his task (string matching) while here's my take in Javascript inputs are two lists of numbers of matching length.
const magnitude = vec => {
const squaredTotal = vec.map(num => Math.pow(num, 2)).reduce((a, b) => a + b) // sum of squares
const mag = Math.sqrt(squaredTotal) // squared root
return mag
}
const dotProduct = (vec1, vec2) => {
if (vec1.length !== vec2.length) {
throw 'vector lengths are not similar. please make sure vector 1 and vector 2 have the same length.'
}
const sumOfMultiplications = vec1
.map((vec, i) => vec * vec2[i]) // multiply each scalar in the vector
.reduce((a, b) => a + b) // sum
return sumOfMultiplications
}
const cosineSimilarity = (vector1, vector2) => {
const sim =
dotProduct(vector1, vector2) / (magnitude(vector1) * magnitude(vector2))
return sim
}
export default cosineSimilaritythe highlighted part is the mathematical formula for cosine similarity in Javascript.
this is the formula.